Country Profiling Using PCA and Clustering¶
Introduction¶
The data from this analysis is from kaggle Unsupervised Learning on Country Data, which contains socio-economic and health related factors of 167 countries over the world. The goal of the project is to categorise the countries using socio-economic and health factors that determine the overall development of the country.
The variables provided in the dataset include socio-economic factors such as export, import and GDP of a country, as well as heath-related factors such as child mortality rate, life expectancy and health spend % of a country. The data is relatively well formatted and unlablled. Due to the nature of the dataset, the analysis will use a combinatino of Unsupervised Machine Learning techniques such as kmeans clustering and Dimensionality Reduction techniques such as Principal Component Analysis. We'll also perform outlier analysis and scalling the data to provide a more accurate clustering result.
Loading data and libraries¶
The analysis starts with loading data and necessary library.
# Load necessary library
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import Normalizer
from sklearn.preprocessing import MinMaxScaler, StandardScaler, RobustScaler
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
from sklearn import metrics
import warnings
warnings.filterwarnings('ignore')
plt.style.use('seaborn')
%matplotlib inline
# set default plot size
plt.rcParams["figure.figsize"] = (15,8)
# Load and preview data
country = pd.read_csv("/Users/leo/Personal/GitHub/Unsupervised_Learning_Country_Clustering/Country-data.csv")
country.head()
# print(country.shape)
Exploratory Data Analysis¶
After the data being loaded, we can see that there are a total of 167 countries and 9 features/factors in the dataset. Using describe() to provide a descriptive statistics, we can see that some of the variables such as GDP and income have some extreme values.
# Summary Statistics
country.describe()
# Check each column for nas
country.isnull().sum()
By plotting a spirplot, we can get a better understanding of how the data are distributed. We can also see that some of the variables have strong linear or non-linear correlations between each other. To further explore them, we'll use corr() function to generate a correlation matrix.
sns.pairplot(country.drop('country',axis=1))

country_cor = country.drop('country',axis=1).corr()
country_cor
# Generate a mask for the upper triangle
mask = np.triu(np.ones_like(country_cor, dtype=np.bool))
# Set up the matplotlib figure
fig, ax = plt.subplots(figsize=(15, 8))
# Generate a custom diverging colormap
cmap = sns.diverging_palette(220, 10, as_cmap=True)
# Draw the heatmap with the mask and correct aspect ratio
sns.heatmap(country_cor, mask=mask, cmap=cmap, vmax=.3, center=0,
square=True, linewidths=.5, cbar_kws={"shrink": .5},annot = True)

The heat map above shows that some of the variables are strongly correlated. For example:
- income and GDP per capita
- child mortality rate and life expectancy
- imports and exports
To address and minimize the extreme value issues, we need to perform some kind of scalling to the dataset. One of the most commen method is the MinMaxScaler(). We'll store the scalled dataset to a new dataframe called country_scale_df
# scale the data
min_max_scaler = MinMaxScaler()
country_scale = min_max_scaler.fit_transform(country.drop('country',axis=1))
country_scale_df = pd.DataFrame(data = country_scale,
columns=country.columns[1:])
country_scale_df['country'] = country['country']
country_scale_df.head()
Principal Component Analysis¶
Pricipal Component Analysis (PCA) is a Dimensionality Reduction technique usually used in large datasets with multiple dimensions, by transforming a large set of variables into a smaller one that still contains most of the information in the original dataset.
We start the PCA by starting an instance of it using PCA() and fit it with the scaled country data. The optimal number of Principal compenent are chosen by picking the minimum number of components that demonstrates the highest amount of variance.
After plotting the the cumulative summation of the explained variance with the number of Principal components, we can see that the optimal number of Principal Components are 5. Compared with the original dataset which have 9 dimensions, PCA have reduced the dimension to 5 and still able to explain over 95% of the variance of the dataset.
# pass through the scaled data set into our PCA class object
pca = PCA().fit(country_scale)
# plot the Cumulative Summation of the Explained Variance
plt.figure()
plt.plot(np.cumsum(pca.explained_variance_ratio_))
# define the labels & title
plt.xlabel('Number of Components', fontsize = 15)
plt.ylabel('Variance (%)', fontsize = 15)
plt.title('Explained Variance', fontsize = 20)
# show the plot
plt.show()

We then use 5 as n_component parameter and save the PCA dataset into a new object called country_pca, this dataset will be used to preform the final clustering.
# we will choose 5 pca components and create a new dataset
country_pca = PCA(n_components=5).fit(country_scale).transform(country_scale)
# store it in a new data frame
country_pca= pd.DataFrame(data = country_pca, columns = ['principal component 1', 'principal component 2',
'principal component 3','principal component 4',
'principal component 5'])
# country_pca['country'] = country['country']
country_pca.head()
country_pca_cor = country_pca.corr()
# Generate a mask for the upper triangle
mask = np.triu(np.ones_like(country_pca_cor, dtype=np.bool))
# Set up the matplotlib figure
fig, ax = plt.subplots(figsize=(15, 8))
# Generate a custom diverging colormap
cmap = sns.diverging_palette(220, 10, as_cmap=True)
# Draw the heatmap with the mask and correct aspect ratio
sns.heatmap(country_pca_cor, mask=mask, cmap=cmap, vmax=.3, center=0,
square=True, linewidths=.5, cbar_kws={"shrink": .5},annot = True)

Kmeans Clustering¶
Kmeans clustering is one of the most commenly used clustering algorithm due to its easy inplementation. The only parameter we need to define for Kmeans clustering is the number of K.
There are many different methods to define the optimal number of k, the most commenly used one is called the elbow method. Below is how to read the elbow plot from geeksforgeeks.com.
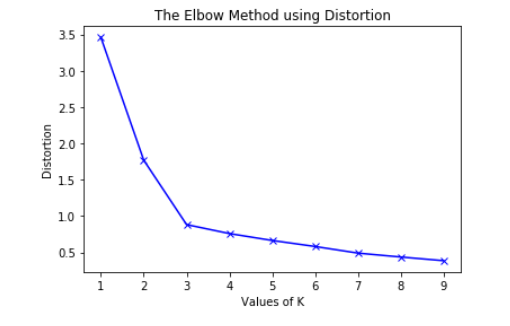
To determine the optimal number of clusters, we have to select the value of k at the “elbow” ie the point after which the distortion/inertia start decreasing in a linear fashion. Thus for the given data, we conclude that the optimal number of clusters for the data is 3.
The metric for sklearn Kmeans distortion/inertia is stored in inertia_ variable and we'd like to try multiple k values to see how the inertia changes for different k value.
# define a dictionary that contains all of our relevant info.
results = []
# define how many clusters we want to test up to.
num_of_clusters = 10
# run through each instance of K
for k in range(2, num_of_clusters):
print("-"*100)
# create an instance of the model, and fit the training data to it.
kmeans = KMeans(n_clusters=k, random_state=0).fit(country_pca)
# store the different metrics
# results_dict_pca[k]['silhouette_score'] = sil_score
# results_dict_pca[k]['inertia'] = kmeans.inertia_
# results_dict_pca[k]['score'] = kmeans.score
# results_dict_pca[k]['model'] = kmeans
results.append(kmeans.inertia_)
# print the results
print("Number of Clusters: {}".format(k),kmeans.inertia_)
Then we plot the Elbow Method for optimal k, we can see that the optimal k value will be 3.
plt.plot(range(2, num_of_clusters), results, 'bx-')
plt.xlabel('k')
plt.ylabel('Sum_of_squared_distances')
plt.title('Elbow Method For Optimal k')
plt.show()

Another good way to determine the optimal k is called Silhouette analysis, It can be used to study the separation distance between the resulting clusters. The silhouette plot displays a measure of how close each point in one cluster is to points in the neighboring clusters and thus provides a way to assess parameters like the number of clusters visually. This measure has a range of (-1, 1).
Silhouette coefficients (as these values are referred to as) near +1 indicate that the sample is far away from the neighboring clusters. A value of 0 indicates that the sample is on or very close to the decision boundary between two neighboring clusters and negative values indicate that those samples might have been assigned to the wrong cluster.
With the help of yellowbrick package, we can use SilhouetteVisualizer() to visualized the Silhouette score for different k. What we are looking for is that each cluster exceeds the red line or the average silhouette score and that the clusters are as evenly distributed as possible. We are only going to focus on k = 2, k = 3 and k = 4 since based on the elbow method, these are the possible choices.
We can see that although for all k, each cluster are above the red line, but only when k = 3 provides a more evenly distributed cluters, so both methods indicate that we should choose k = 3 for out Kmeans clustering.
# From the graph above, it indicates that we should choose k = 3
from yellowbrick.cluster import SilhouetteVisualizer
clusters = [2,3,4]
for cluster in clusters:
print('-'*100)
# define the model for K
kmeans = KMeans(n_clusters = cluster, random_state=0)
# pass the model through the visualizer
visualizer = SilhouetteVisualizer(kmeans)
# fit the data
visualizer.fit(country_pca)
# show the chart
visualizer.poof()
# the silhouette plot also shows that the optimal k is 3



The last step is to apply the kmeans clustering to the data and get the lables of which cluster each country falls into.
kmeans = KMeans(n_clusters=3, random_state=0).fit(country_pca)
country['cluster'] = kmeans.labels_
country.head()
Print out the country in each cluster
Cluster 1
country[country['cluster'] == 0][:10]
Cluster 2
country[country['cluster'] == 1][:10]
Cluster 3
country[country['cluster'] == 2][:10]
By looking at the output of the countries in each cluster, combined with our knowledge on some of the countries. We can see that:
- Cluster 1 are those less developed countries, most of which are in Africa
- Cluster 2 are those developed countries, most of which are in Europe, North America and some part of Asia
- Cluster 3 are thoe developing countries, most of whic are in South America and Asia